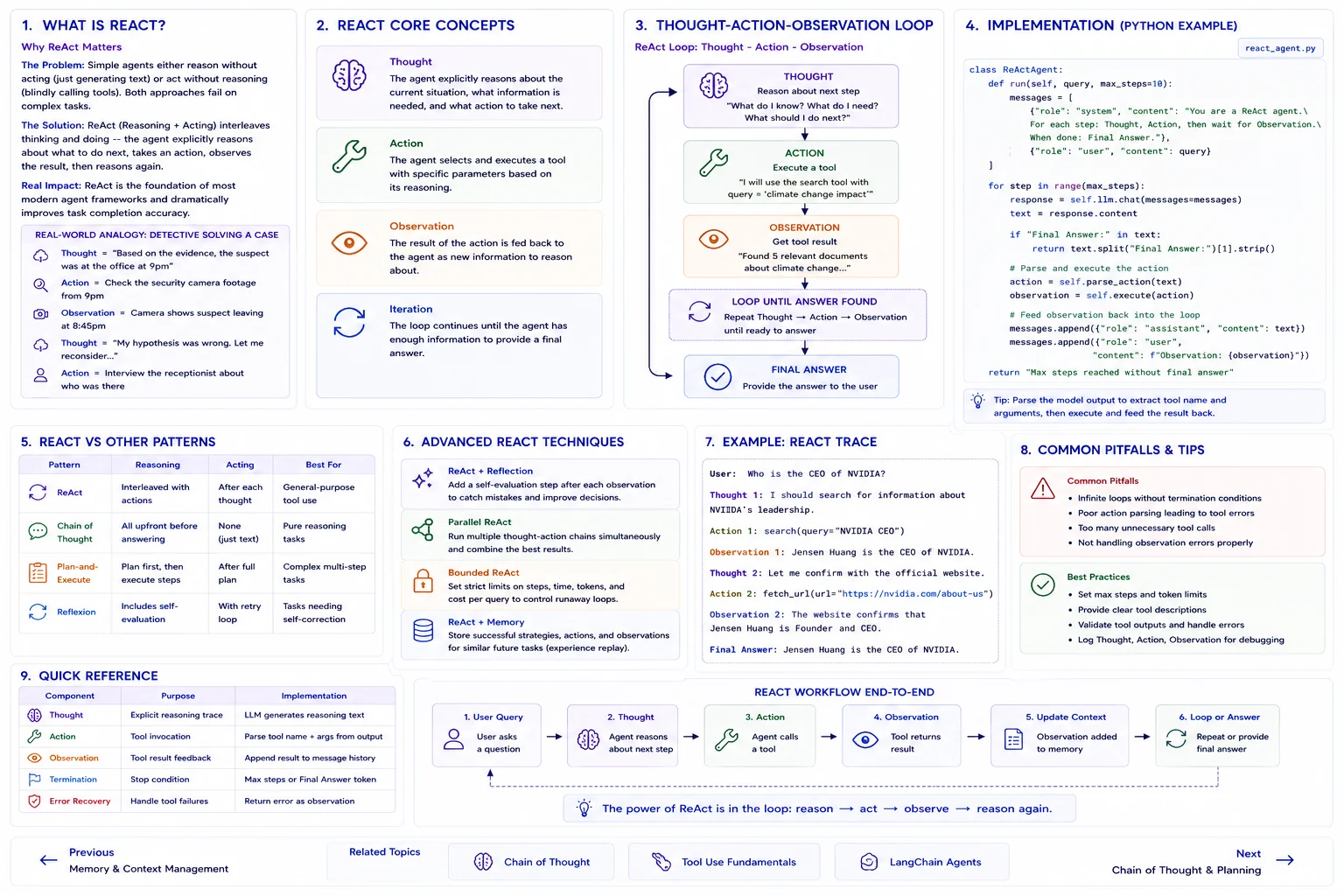
What is ReAct?
Why ReAct Matters
The Problem: Simple agents either reason without acting (just generating text) or act without reasoning (blindly calling tools). Both approaches fail on complex tasks.
The Solution: ReAct (Reasoning + Acting) interleaves thinking and doing -- the agent explicitly reasons about what to do next, takes an action, observes the result, then reasons again.
Real Impact: ReAct is the foundation of most modern agent frameworks and dramatically improves task completion accuracy.
Real-World Analogy
Think of ReAct like a detective solving a case:
- Thought = "Based on the evidence, the suspect was at the office at 9pm"
- Action = Check the security camera footage from 9pm
- Observation = Camera shows suspect leaving at 8:45pm
- Thought = "My hypothesis was wrong. Let me reconsider..."
- Action = Interview the receptionist about who was there
ReAct Core Concepts
Thought
The agent explicitly reasons about the current situation, what information is needed, and what action to take next.
Action
The agent selects and executes a tool with specific parameters based on its reasoning.
Observation
The result of the action is fed back to the agent as new information to reason about.
Iteration
The loop continues until the agent has enough information to provide a final answer.
Thought-Action-Observation Loop
Implementation
class ReActAgent:
def run(self, query, max_steps=10):
messages = [
{"role": "system", "content": "You are a ReAct agent. For each step: Thought, Action, then wait for Observation. When done: Final Answer."},
{"role": "user", "content": query}
]
for step in range(max_steps):
response = self.llm.chat(messages=messages)
text = response.content
if "Final Answer:" in text:
return text.split("Final Answer:")[1].strip()
# Parse and execute the action
action = self.parse_action(text)
observation = self.execute(action)
# Feed observation back into the loop
messages.append({"role": "assistant", "content": text})
messages.append({"role": "user",
"content": f"Observation: {observation}"})ReAct vs Other Patterns
| Pattern | Reasoning | Acting | Best For |
|---|---|---|---|
| ReAct | Interleaved with actions | After each thought | General-purpose tool use |
| Chain of Thought | All upfront | None | Pure reasoning tasks |
| Plan-and-Execute | Plan first, then execute | After full plan | Complex multi-step tasks |
| Reflexion | Includes self-evaluation | With retry loop | Tasks needing self-correction |
Advanced ReAct
Advanced Techniques
- ReAct + Reflection: Add a self-evaluation step after each observation
- Parallel ReAct: Run multiple thought-action chains simultaneously
- Bounded ReAct: Set strict limits on steps and cost per query
- ReAct + Memory: Store successful strategies for similar future tasks
Quick Reference
| Component | Purpose | Implementation |
|---|---|---|
| Thought | Explicit reasoning trace | LLM generates reasoning text |
| Action | Tool invocation | Parse tool name + args from output |
| Observation | Tool result feedback | Append result to message history |
| Termination | Stop condition | Max steps or Final Answer token |
| Error Recovery | Handle tool failures | Return error as observation |